A little bit theory on unconstrained optimization
In unconstrained optimization one wishes to minimize or maximize a given function , the so called objective function, without further constraints. We stick here on minimization, maximization may be done then by reversing the sign of . Without some additional assumptions the task might not be solvable at all, hence we present here some (not too hard) restrictions on which give us a well defined environment to work in.
General assumptions
- The domain of is open in .
- There is a
such that the level set
is closed and bounded in (i.e. compact). - is two times continuously differentiable on an open neighborhood of .
- There exists a
in
such that
- If
is a local minimizer in
, i.e.
for some , then there holds
the so called necessary first and second order optimality conditions. - If
and
is positive definite,
then
is a strict local minimzer of
, i.e.
for some . A sufficient strict local optimality condition.
Silently one hopes that from the fact that by construction of the methods there holds a strict monotonic decrease of some associated sequence of function values if might follow, that the limit point one obtains will be a strict local minimizer. There exist methods which indeed guarantee to obtain the global minimizer, but these are of a completely different structure from those presented here. The general structure of most of the methods in this chapter is as follows: Given (hopefully as assumed above) one computes a sequence from
where is strictly gradient related, this means
and
for some constants which are implicit in the construction of , not necessarily explicitly known. In words: the direction of change is of comparable length with the current gradient and has an angle with it, which is bounded away from . Mostly this property is obtained by choosing as the solution of a linear system
with a sequence of matrices , whose eigenvalues are bounded from below by a positive constant and bounded from above too. Such a sequence of matrices is called uniformly positive definite. The stepsize is computed such that it satisfies the so called principle of sufficient decrease:
and
is an explicitly known constant, provided by the user (in the codes in this chapter it is the parameter ) and should be chosen less than 0.5 for efficiency reasons. The existence of is assured by the assumptions on and the construction of , but it is usually unknown. Inserting all the above one gets
and from the boundedness of from below that
and from this that every limit point of is a first order necessary point. Clearly has limit points. One also gets
Hence if is also bounded one gets
and if has only finitely many stationary points then the whole sequence must converge to one of these. This is what a user hopes for: the code delivers a sequence such that termination with
delivers him a result "near" a true solution. Up to a second order term the error will be
hence if the method delivers a such that
(the so called Broyden-Dennis-Morè condition) then termination on grounds of a small difference in will also be a reliable one. We mentioned the construction of above already. The codes in use satisfy this, sometimes with constructed explicitly, sometimes with existing but not known explicitly. We now turn to the computation of the stepsize . Two methods are in use here: The simplest one is known as backtracking or Goldstein-Armijo descent test and works as follows: Given a strictly gradient related direction choose some initial stepsize less than some universal constant (often =1). Then take as the largest value which satisfies
with a parameter , (often ) and , preferably .
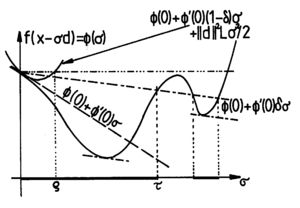
is often useful. The picture above shows you the graph of a function, its tangent line at , the "Armijo line" used in the test, two intervals of admissible stepsizes and the local upper bound on , a parabola in which the upper bound for on the enters. This parabola is used to prove that there always are stepsizes satisfying the principle of sufficient decrease. The drawback of dependency on is avoided by the so called Powell-Wolfe stepsize which is independent of such: here a stepsize is computed such that
with . Sometimes the strong Powell-Wolfe conditions are used, where on the left hand side of the second inequality the absolute sign is used. This means that a local first order stationary point on the search line is required.
File translated from TEX by TTM Unregistered, version 4.03.
On 16 Jun 2016, 18:14.