Next: About this document ...
All methods for nonlinear optimization which are available here use the same model, namely

Silently we assume that points satisfying the constraints exist.
It is good advise that a user makes every possible effort to find
as his initial guess for a solution a ![]() which satisfies the
constraints or at least comes near to do so, since in the nonlinear
case it is quite easy to devise examples there none of the methods known
will succeed from a bad
which satisfies the
constraints or at least comes near to do so, since in the nonlinear
case it is quite easy to devise examples there none of the methods known
will succeed from a bad ![]() , although a well behaved solution exists.
In the codes infeasibility of the problem will be reported
as a failure in reducing the infeasibility below a user defined bound.
, although a well behaved solution exists.
In the codes infeasibility of the problem will be reported
as a failure in reducing the infeasibility below a user defined bound.
The formulation above suggests that we search for the globally best
value of ![]() on the whole set described by the constraints, and indeed
a typical user will hope for this.
There are known methods for this, known as deterministic global
optimizers, but they are presently limited to rather small dimensions
and extremely cumbersome.
on the whole set described by the constraints, and indeed
a typical user will hope for this.
There are known methods for this, known as deterministic global
optimizers, but they are presently limited to rather small dimensions
and extremely cumbersome.
Practically we here are only able to
identify so called first order stationary points (also known as
''Kuhn-Tucker points''). Even the characterization of these
stationary points (from your calculus course you will know
the condition
![]() for the unconstrained case)
requires additional conditions. We present here only the two practically
important ones, (although weaker conditions exist), namely
for the unconstrained case)
requires additional conditions. We present here only the two practically
important ones, (although weaker conditions exist), namely
| LICQ | linear independence condition |
|
| MFCQ | Mangasarian-Fromowitz condition | |
|
|
The notation ![]() for a vector function of
for a vector function of ![]() components
means a matrix obtained
by writing the gradients of the components of
components
means a matrix obtained
by writing the gradients of the components of ![]() (which have
(which have ![]() components themselves) side by side, i.e. a
components themselves) side by side, i.e. a ![]() matrix,
the transposed Jacobian.
matrix,
the transposed Jacobian.
The direction ![]() in MFCQ is one which moves
in MFCQ is one which moves ![]() along
along ![]() towards strong feasibility with respect to the active inequalities
and deteriorates the equalities at most of second order
in
towards strong feasibility with respect to the active inequalities
and deteriorates the equalities at most of second order
in ![]() .
The MFCQ is equivalent to
.
The MFCQ is equivalent to
Now here comes the characterization theorem:
If ![]() is a local solution of NLO and either LICQ or MFCQ hold, then
there exists so called multipliers
is a local solution of NLO and either LICQ or MFCQ hold, then
there exists so called multipliers ![]() and
and ![]() , such that the following
holds:
, such that the following
holds:

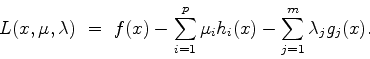
If LICQ holds, then the multipliers belonging to a local solution point
![]() are unique. They may be obtained solving the formally overdetermined
system
are unique. They may be obtained solving the formally overdetermined
system
LICQ is a very strong condition. On the other side one sees the importance of MFCQ from the fact, that the set of possible multipliers in the Kuhn-Tucker conditions is bounded if and only if MFCQ holds. Once more a warning concerning equality constraints with linearly dependent gradients.
The Kuhn-Tucker conditions are sufficient optimality conditions if the problem
is convex, i.e. ![]() is convex, all the components
is convex, all the components ![]() of
of ![]() are concave and
are concave and
![]() is affinely linear. In this special situation and if
is affinely linear. In this special situation and if ![]() is even
strictly convex (such that the minimizer is unique) and there exists
a feasible point with
is even
strictly convex (such that the minimizer is unique) and there exists
a feasible point with ![]() for all nonlinear
for all nonlinear ![]() (this is the so called Slater condition) the solution of the problem
NLO can be obtained by a problem of much simpler structure, namely
(this is the so called Slater condition) the solution of the problem
NLO can be obtained by a problem of much simpler structure, namely
For the nonconvex case there exist local optimality criteria. We cite here only
the simplest version, in which the so called
''strict complementarity condition''
This positivity condition can be reduced to a simple positive definiteness
check for the so called ''projected Hessian'': if ![]() is an orthonormal basis
of the null space of the matrix
is an orthonormal basis
of the null space of the matrix
![]() then one simply has to test
then one simply has to test ![]() for positive definiteness, for example by
trying its Cholesky decomposition.
In the prepared testcases the two extreme eigenvalues of
for positive definiteness, for example by
trying its Cholesky decomposition.
In the prepared testcases the two extreme eigenvalues of ![]() are reported.
are reported.